

控制图到底该抽多少样本?25组×5个的科学依据,不仅仅是经验值!
关键词:质量管理,统计过程控制,SPC,抽样,控制图
导语: 在质量管理和统计过程控制(SPC)中,"抽取25组,每组5个样本"几乎是一条金科玉律。但很多老师只告诉你这是"经验值",背后其实有严格的统计计算逻辑。今天一次讲清楚为什么是25组,以及为什么是每组5个。

一、先搞清楚核心问题:我们在平衡什么?
设计控制图时,本质上是三个目标的博弈:
估计精度:对过程标准差的估计有多准?
检测能力:过程出现异常时,多快能发现?
经济性:抽样成本是否可接受?
"25组×5个"这个组合,正是这三个维度下的最优平衡点。
二、为什么是每组5个?检测能力与成本的黄金分割
首先和漏报概率β有关系,就是实际已经发生偏移,但控制图没报警的概率,计算公式是:
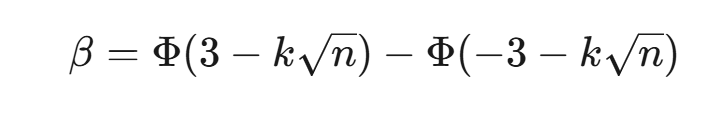
Φ:累积分布函数,Cumulative Distribution Function,CDF
k :过程均值偏移量(以标准差 σ 为单位,如 k=1 表示偏移 1σ )
n :每组样本量
3:对应 3σ 控制限的 z 值
假设
• 每组样本量 n=5
• 过程实际偏移了 1σ (即 k=1 )
• 使用常规的 3σ 控制限
通过公式计算可得 β=77.8%,说明:
当过程偏移 1σ 时,有 77.8% 的概率检测不出来(漏报)。
只有 1−0.778=22.2% 的概率能正确报警。
平均需要 ARL=1/( 1−β)=1/0.222≈4.5组才能检出这个偏移。
关键概念:ARL(平均运行长度)
ARL(Average Run Length)指的是:从过程发生偏移开始,到控制图首次报警平均需要多少组样本。
ARL越小越好——意味着我们能更快发现问题。
以此类推,假设过程发生了1倍标准差(1σ)的小偏移,分别去1~7个样品的检测概率如下表所示:
|
样本量 |
漏报概率 |
检测概率 |
ARL(平均需多少组发现) |
评价 |
|
每组1个 |
97.7% |
2.3% |
43.9组 |
极差,几乎无法检测 |
|
每组2个 |
94.4% |
5.6% |
17.8组 |
响应太慢 |
|
每组3个 |
89.8% |
10.2% |
9.8组 |
可接受,但偏慢 |
|
每组4个 |
84.1% |
15.9% |
6.3组 |
良好 |
|
每组5个 |
77.8% |
22.2% |
4.5组 |
最优平衡点 |
|
每组6个 |
70.9% |
29.1% |
3.4组 |
检测力↑但成本↑ |
|
每组7个 |
63.8% |
36.2% |
2.8组 |
R图效率开始下降 |
解读:
n=5时,ARL=4.5组:意味着过程偏移后,平均只需4.5组(约5组)就能报警,响应速度可接受。
相比n=4(6.3组),检测效率提升29%;相比n=6(3.4组),成本降低但检测力损失不大。
那如果检测大偏移呢?
使用同样方法可以计算如果过程发生2σ偏移(较明显的异常):
n=5时,检测概率达92.95%,ARL仅1.08组——几乎是立即检出。
而n=3-4也能做到1.2-1.5组,但n=5更保险。
如果发生3σ偏移(严重异常):
n=5的检测概率达99.99%,瞬时检出,与n=6、7几乎没有差别。
结论: 对于最常见的1σ小偏移,n=5是性价比最高的选择;对于大偏移,n=5已经足够灵敏。再大的样本量(n≥6)边际效益递减,反而增加检验成本,且会影响极差(R)控制图的效率。如果要检测小于1σ的微小偏移,需配合CUSUM累积和控制图/EWMA指数加权移动平均控制图,而非单纯增大样本数n。
三、为什么是25组?标准差估计的精度保障
控制限的可靠性完全取决于你对过程标准差(σ)的估计精度。估计不准,控制限就"形同虚设"。
关键概念:COV(变异系数)
COV(Coefficient of Variation)用来衡量标准差估计值的相对误差:
COV = 1/√(2×自由度df)
COV越小,说明σ估计越准,控制限越可靠。
自由度df如何计算?
在Xbar-R图(均值极差控制图)中,自由度公式为:
df = 0.9×k×(n-1) (k为组数,n为每组样本数)
当n=5,k=25时:
df = 0.9×25×4 = 90
实际上25组×5个的实际自由度约为90,对应COV≈7.5%。
不同组数的精度对比
|
组数(k) |
自由度(df) |
COV(估计误差) |
控制限可靠性 |
评价 |
|
10组 |
36 |
11.8% |
太"软" |
误差大,风险高 |
|
20组 |
72 |
8.3% |
可接受 |
下限标准 |
|
25组 |
90 |
7.5% |
推荐标准 |
精度与成本的平衡 |
|
30组 |
108 |
6.8% |
更好 |
边际收益递减 |
为什么是25组?
1. 精度达标:COV≈7.5%意味着标准差估计误差控制在7.5%左右,这是一个保险值而非最低要求。
2. 安全边际:实际工作中难免遇到异常值。即使剔除3-4个异常组,剩余21-22组的COV仍保持在8-9%可接受范围。
3. 经济性:从25组增加到30组,COV仅从7.5%提升到6.8%,精度提升有限但成本增加20%,性价比不高。
(数据来源:Douglas Montgomery《Statistical Quality Control》)
四、实用速查指南
根据不同的监控需求,样本量选择策略:
|
检测目的 |
推荐样本量 |
理由 |
|
仅检测大偏移(≥3σ) |
n=2-3 |
成本低,瞬时检出 |
|
检测中等偏移(2σ) |
n=3-4 |
ARL≈1.2-1.5,响应迅速 |
|
检测小偏移(1σ)+成本控制 |
n=5 |
ARL=4.5,性价比最优 |
|
检测微小偏移(<1σ) |
n≥6+特殊控制图 |
需配合CUSUM累积和图或EWMA图,而非单纯增大n |
结语:从"经验"到"科学"
"25组×5个"不是拍脑袋的经验值,而是统计计算与工程实践的完美结合:每组5个:在检测1σ偏移时达到ARL=4.5组的黄金平衡点,兼顾了小偏移检测力和抽样成本。
25组:确保标准差估计的COV≈7.5%,即使剔除部分异常数据仍有足够的安全边际。
下次再有人问你为什么抽这么多,你可以自信地告诉他:这背后是漏报概率、ARL、COV的精密计算,是质量工程的最优解!
作者:谢鸣 (Frank),制造型企业质量及精益改善专家,六西格玛黑带。拥有20余年质量和精益领域工作经历,先后任职于西门子、施耐德等国际知名企业。